What is an Embedding? And Why Should Devs Care?
Arman
If you're venturing into AI-powered applications, understanding embeddings is crucial. In this post, I’ll show you exactly what they are — and how to use them in a modern TypeScript stack with PostgreSQL + pgvector. Let's demystify this concept.
What Is an Embedding?
An embedding is a vector—a list of numbers—that captures the meaning of a piece of data, such as text, images, or audio. It transforms:
✍️ Text → 🧠 Meaning → 🔢 Vector
"I love programming."
becomes →[0.123, 0.089, ..., 0.245](1536 dimensions)
Similar texts = similar vectors (close in distance).
Example:
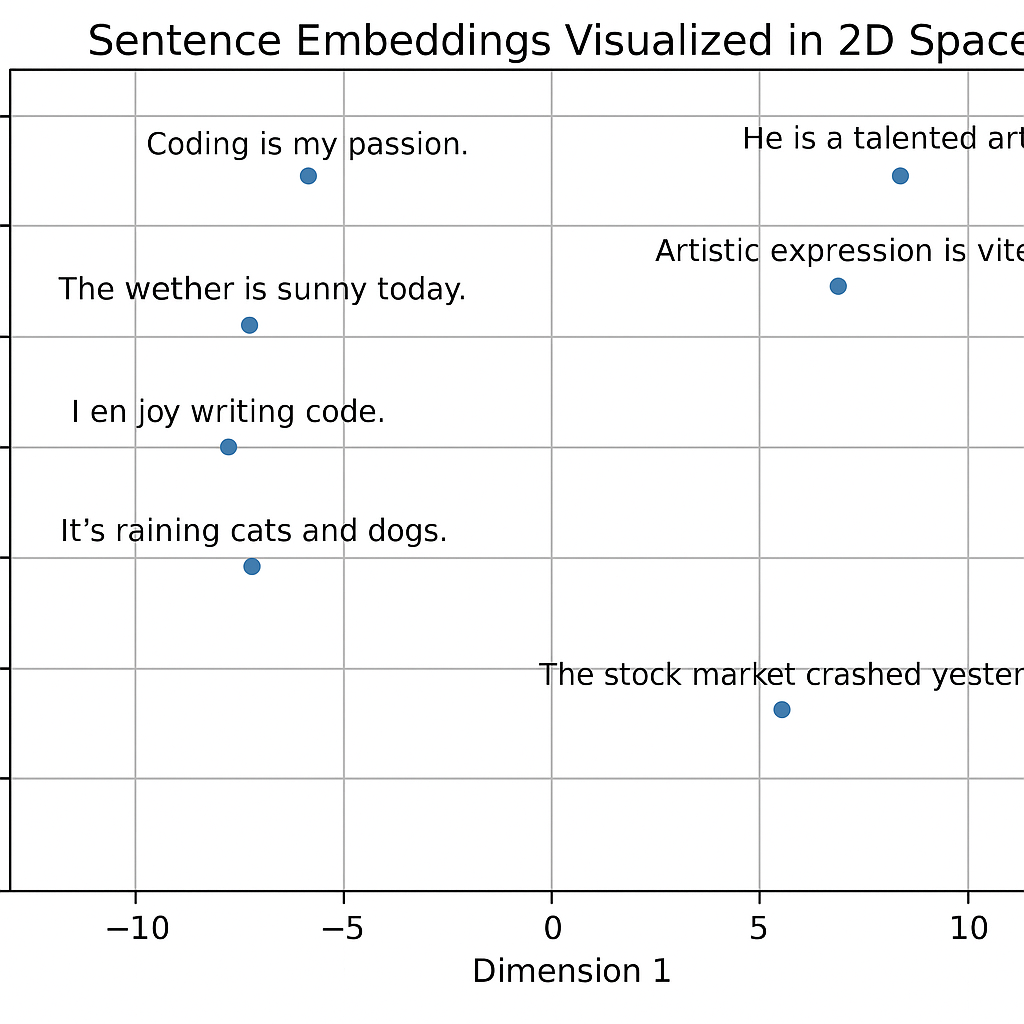
Consider these two sentences:
-
“I love programming.”
-
“Coding is my passion.”
These have different words but similar meaning. Their embeddings—numerical representations—are close in vector space, reflecting their semantic similarity.
So… How Are Embeddings Generated?
Embedding models (like text-embedding-ada-002 from OpenAI or all-MiniLM-L6-v2 from HuggingFace) process your text through a deep neural network trained on massive corpora.
Here’s what they do:
-
Tokenize your input.
-
Process through Transformer layers.
-
Output a vector—e.g., 384 or 1536 floats—that represents that sentence in vector space.
You don’t need to train these from scratch. Just use the APIs.
const response = await fetch('https://api.openai.com/v1/embeddings', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
input: "I love programming.",
model: "text-embedding-ada-002"
})
});
const json = await response.json();
const embedding = json.data[0].embedding; // This is a 1536-dimensional vector
Why Should Developers Care?
Embeddings power:
-
🔍 Semantic Search: Search by meaning, not just keywords.
-
🧠 Chat with Documents: Retrieval-Augmented Generation (RAG).
-
🎯 Recommendation Systems: Suggest similar items based on content.
-
🗂️ Clustering and Classification: Group similar data points.
🛠️ Store Embeddings in PostgreSQL (with pgvector extension)
PostgreSQL supports pgvector, which makes PostgreSQL a full-on vector database.
Step 1: Create the table
Use SQL to create your table with a vector column:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536)
);
Step 2: Insert from TypeScript
import { Pool } from 'pg';
const pool = new Pool({
connectionString: process.env.DATABASE_URL, // Your Neon DB URL
ssl: { rejectUnauthorized: false }
});
await pool.query(
'INSERT INTO documents (content, embedding) VALUES ($1, $2)',
['I love programming.', embedding]
);
🔍 Perform a Semantic Search
Let’s search for the top 5 documents semantically closest to a given input:
const result = await fetch('https://api.openai.com/v1/embeddings', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
input: "Coding is fun",
model: "text-embedding-ada-002"
})
});
const queryVector = (await result.json()).data[0].embedding;
const { rows } = await pool.query(`
SELECT content, embedding <#> $1 AS distance
FROM documents
ORDER BY distance ASC
LIMIT 5
`, [queryVector]);
-
<#>is the cosine distance operator inpgvector. -
Smaller
distance= higher similarity.
🚀 Final Thoughts
Embeddings are not just for ML engineers anymore. With a few lines of TypeScript and a PostgreSQL DB, you can build semantic search, recommendations, AI chat, and more.
All inside your favorite stack.
If you want a starter template using Next.js + Neon + pgvector + OpenAI, let me know — I’ll publish it on GitHub.